

Dữ liệu được gắn nhãn vẫn là tài nguyên hiếm trong nhiều tình huống thực tế của Xử lý Ngôn ngữ Tự nhiên (NLP). Phương pháp duy nhất thường là thu thập và gắn nhãn văn bản thủ công, điều này gây tốn kém và tốn thời gian.
Skweak:được xây dựng dựa trên một ý tưởng rất đơn giản: Thay vì gắn nhãn văn bản thủ công, chúng ta xác định một tập hàm gắn nhãn để tự động chú thích tài liệu, sau đó tổng hợp kết quả để có phiên bản đã gắn nhãn của kho dữ liệu.
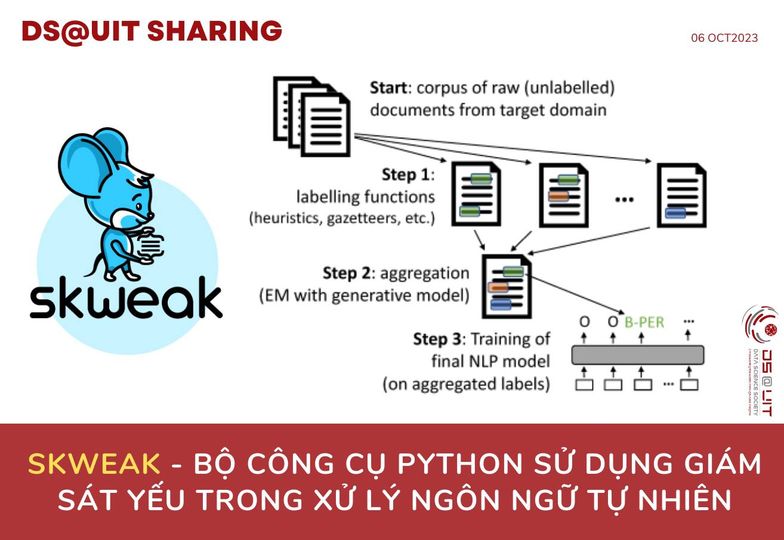
Giám sát yếu với skweak: đi qua các bước sau:
Bắt đầu: Thu thập tập dữ liệu gốc (chưa gắn nhãn). skweak được xây dựng trên nền tảng Spacy, vì vậy bạn cần chuyển đổi tài liệu của mình thành các đối tượng Doc bằng Spacy.
Bước 1: Định nghĩa các hàm gắn nhãn để tự động chú thích các đoạn văn bản với nhãn, sử dụng heuristics, gazetteers hoặc các mô hình học máy,...
Bước 2: Tổng hợp kết quả của chúng để có một chú thích duy nhất, có tính xác suất (thay vì nhiều chú thích có thể xung đột từ các hàm gắn nhãn) bằng cách sử dụng một mô hình tạo sinh để ước tính độ chính xác tương đối và sự nhầm lẫn có thể có của mỗi hàm gắn nhãn.
Bước 3: Dựa trên các nhãn tổng hợp, huấn luyện mô hình cuối cùng của bạn để sử dụng trong nhiệm vụ NLP.
Bộ công cụ skeweak cung cấp một API python để áp dụng các hàm gắn nhãn và tổng hợp kết quả chỉ trong vài dòng mã. Bộ công cụ này có thể áp dụng cho việc gắn nhãn chuỗi và phân loại văn bản, và đi kèm với một loạt các tính năng mới lạ như tích hợp nhãn chưa được xác định rõ và việc tạo ra các hàm gắn nhãn trên cấp độ tài liệu.
Paper : https://aclanthology.org/2021.acl-demo.40.pdf
Github : https://github.com/NorskRegnesentral/skweak
Mọi thông tin chi tiết xem tại: https://www.facebook.com/dsociety.uit.ise/posts/pfbid02KNgojUvSQ2P9g4fSwpGjYdL3TipncCXziGrXa7WQvCnuk4fjgMWhrxncguiUdoCwl
Hạ Băng - Cộng tác viên Truyền thông Trường Đại học Công nghệ Thông tin





